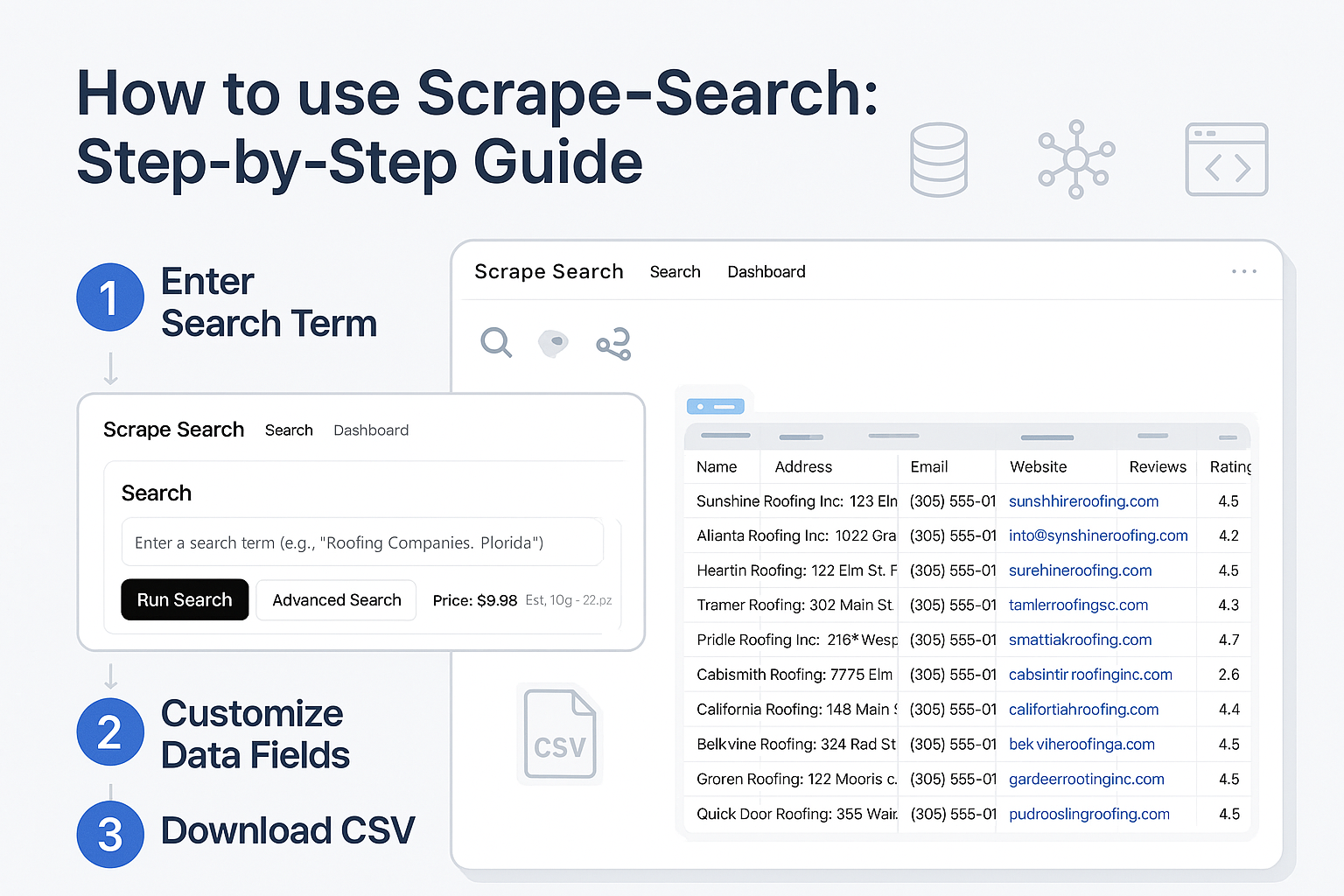
How to Scrape Web Data Using Scrape-Search
How to Scrape Web Data Using Scrape-Search
Web scraping has become an essential method for gathering valuable online data efficiently. If you've been struggling to scrape web data manually, tools like scrape-search.com can simplify the process significantly. In this guide, we'll walk you step-by-step on how to effectively scrape websites for data using Scrape-Search.com. We will walk through the process of creating this search query.
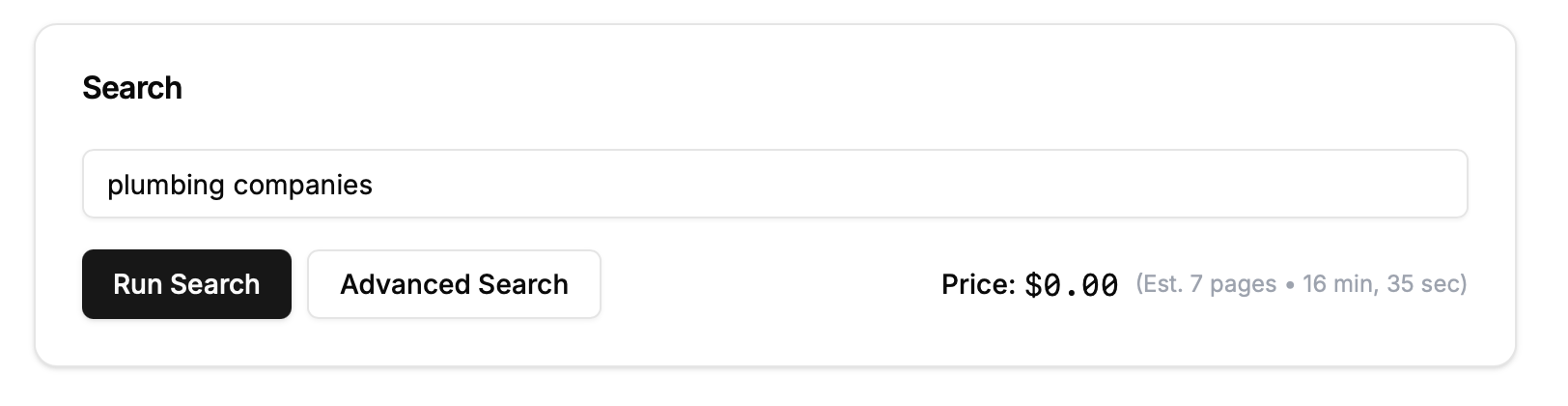
Step 1: Enter Your Search Term
To start scraping web data:
Go to scrape-search.com.
Enter your primary search term, for example, “Plumbing Companies.”
Click “Advanced Search”.
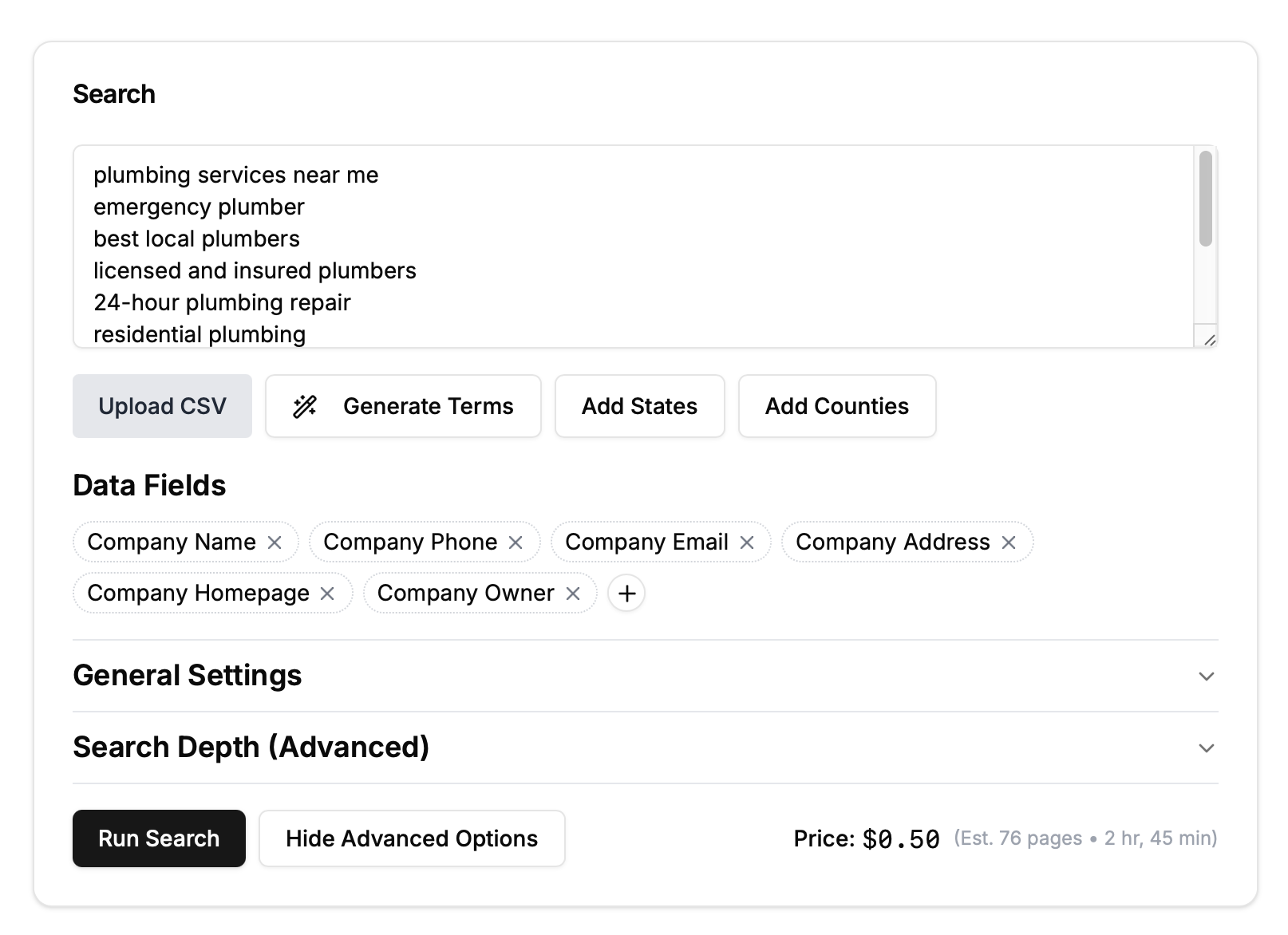
Step 2: Generate Additional Search Terms
Enhance your search to yield more comprehensive results:
Click “Generate Terms”.
Scrape-Search suggests additional relevant keywords like "emergency plumber," "licensed plumbers," and "24-hour plumbing services."
Step 3: Select States and Counties (Optional)
Refine your data geographically:
Click “Add States” or “Add Counties”.
Scrape-Search adds geographical filters such as:
Plumbing Companies California
Plumbing Companies Orange County California
Note: This feature does not work with multiple search terms. Leave it disabled if you have entered multiple search terms or urls.
Step 4: Customize Your Data Fields
To ensure you scrape websites for data relevant to your needs:
Remove unnecessary fields like "Employee Name" or "Employee LinkedIn URL" by clicking the X next to each.
Click “+” to add crucial fields such as "Company Owner."
Your final data fields will appear as columns in the CSV file you'll download later.
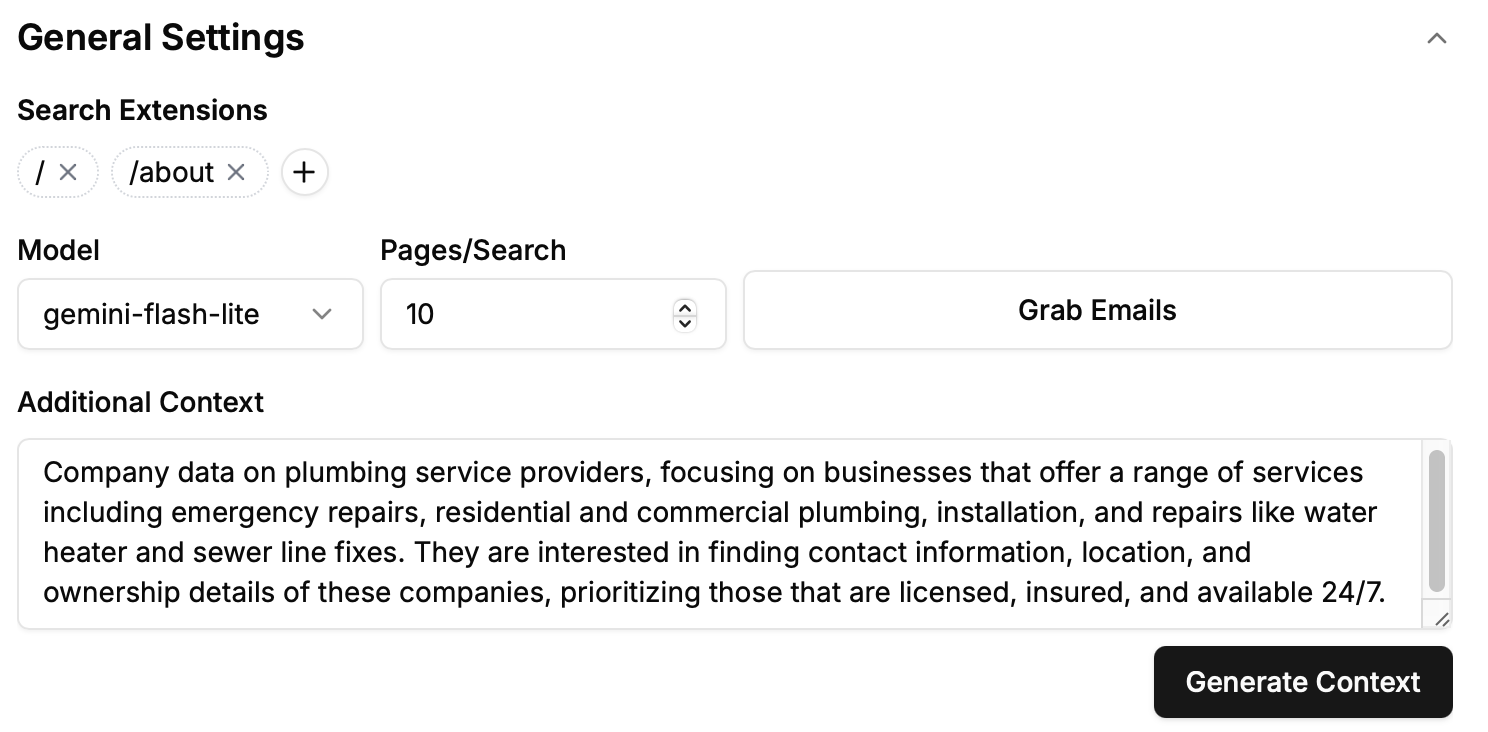
Step 5: Add Search Extensions
Direct your scraping efforts to specific pages on a website:
Click “+” under Search Extensions.
Add targeted pages like
/aboutto help Scrape-Search find essential data pages.
Extensions starting with “/” direct scraping to pages like
example.com/about.Extensions ending with “.” direct scraping to subdomains like
jobs.example.com.
Step 6: Choose Your Model
Select from available AI models for scraping web data:
Gpt-4o: Most accurate but slower and more expensive.
Gpt-4o-mini: Balanced cost and performance.
Gemini-flash: Slightly lower accuracy, budget-friendly.
Gemini-flash-lite: Fastest and cheapest with basic performance.
We'll use Gemini-flash-lite by default for cost-effectiveness.
Step 7: Define Pages / Search
Set the number of pages Scrape-Search will scan:
Default recommended setting is 10 pages.
This determines how many pages of search results are checked per term.
Pages might occasionally be skipped due to:
Websites blocking scraping attempts.
Error-loaded or empty content pages.
Pages failing Scrape-Search validation checks.
We are leaving this at the default value.
Step 8: Grab Emails (Optional)
Enable email scraping if needed:
Checking this box uses Scrape-Search partners to extract emails.
Emails are extracted only from validated homepages—not directories or unrelated pages.
For our plumbing example, this feature will remain unchecked.
Step 9: Provide Additional Context
Give Scrape-Search more specific instructions:
Click “Generate Context”.
Edit the generated context to reflect detailed scraping goals such as contact info, ownership details, licensing, and availability.
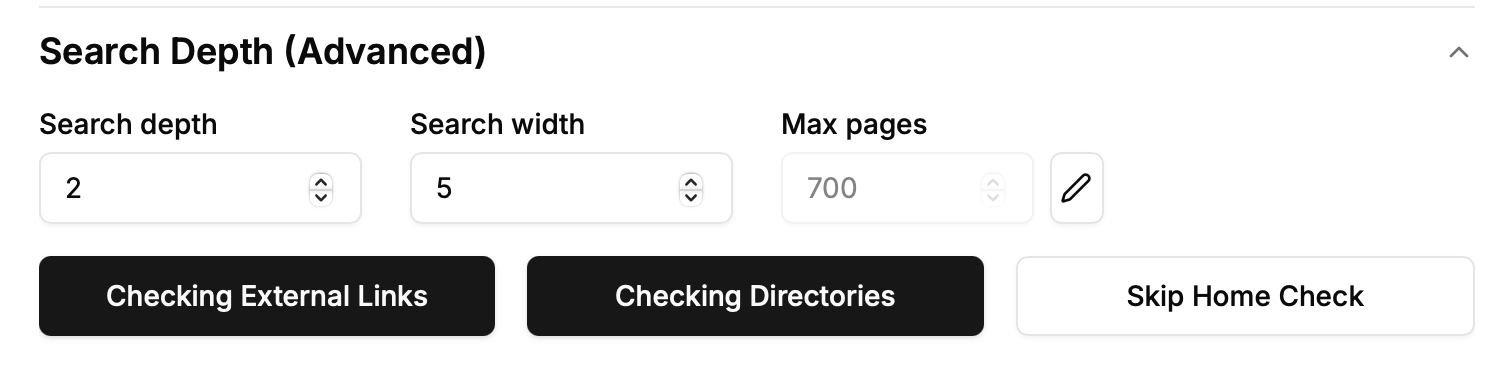
Step 10: Set Search Depth
Control how deep Scrape-Search navigates within websites:
Click the “Search Depth” dropdown.
Initially, Scrape-Search only checks the first page of search results.
Increasing the depth to 2 allows Scrape-Search to navigate links from the initial page (e.g.,
example.com/teamtoexample.com/support).Setting the depth to 3 enables further exploration of links from secondary pages, uncovering more relevant pages.
For this search, we'll set the depth to 2.
Step 11: Define Search Width
Control the breadth of scraping at each depth level:
Search Width determines how many pages Scrape-Search evaluates at each depth level.
For example, with a width of 3, Scrape-Search checks pages like
example.com/support,example.com/about, andexample.com/contact.
We'll set our width to 5 for thorough coverage.
Step 12: Max Pages (Optional)
This forces our scraper to stop once it check a certain number of pages. By default this value is the maximum possible number of pages.
We will leave this untouched for our search purposes.
Step 13: Check External Links
This feature is only activated when depth is greater than 2. It is crucial when your search results include many directories or external listings:
By default, Scrape-Search stays within the initial domain (internal depth).
Enabling “Check External Links” allows Scrape-Search to follow links leading outside the initial domain, crucial for blue-collar or service-based listings often found on directory-style pages, like Best Plumbers in NYC.
With this enabled, Scrape-Search navigates directly to external websites, ensuring accurate and relevant data collection.
We are clicking this to search for external pages.
Step 14: Check Directory Pages
Use this to directly scrape valuable details from directory-style pages:
Check Directory Pages allows immediate data extraction from listings, capturing key information such as company names, addresses, websites, and descriptions directly from directory pages.
Especially beneficial if your targeted businesses frequently rely on directory listings rather than dedicated websites.
Typically paired with external link checking for optimal results.
We are enabling this so that Scrape-Search will look through external links.
Step 15: Skip Homepage Check (Optional)
By default we check that the homepage is relevant to the search term. If the search result page is example.com/listings, then it will check that example.com is relevant. Skip validating homepage relevance to extract data directly from search results:
Ideal when paired with directory scraping, ensuring data extraction without requiring homepage confirmation.
We're leaving this unchecked to ensure homepage accuracy and relevancy.
For our search we will leave this on the default option, as we are only going to extract data from websites that are plumbing websites.
Step 16: Start Your Search and Export Data
Click “Run Search”.
Monitor the scraping progress.
Once complete, click “Download CSV” to obtain your scraped data.
Price, Estimate Pages, Estimated Time
Due to the complex machine learning at hand we have no way of knowing the exact # of results we will yield. We provide an estimate of the valid number of pages that we will end up extracting data but this is a rough estimate.
We also provide an estimate of how long a search will take based on the number of pages we’re checking but this can also drastically vary.
Price is based on the model and total number of pages we will check.


